Meituan's first video large model is open-sourced, with its speed soaring by 900%.
default / 2021-11-15
Meituan regards this as its first step toward building a world model.
Reported by Zhidongxi on October 27, Meituan open-sourced its first video generation large model—LongCat-Video—on October 25. Targeting multi-task video generation scenarios, the model aims to support three capabilities (text-to-video, image-to-video, and video continuation) with a unified architecture.
Unlike previous models trained for single tasks, LongCat-Video can process zero-frame, single-frame, and multi-frame conditional inputs within the same framework through a multi-task joint training mechanism.
In addition, LongCat-Video has made key breakthroughs in long video generation, natively supporting the output of 5-minute-long videos. Compared with common issues like frame drift and color shift that plague most models in long-sequence generation, this model maintains high temporal consistency and visual stability through native pre-training on video continuation tasks.
In terms of inference efficiency, LongCat-Video draws on advanced efficient generation methods developed in recent years, adopting a "coarse-to-fine" two-stage generation strategy: first generating 480p, 15fps videos, then refining them to 720p, 30fps. Combined with block-sparse attention mechanism and model distillation, it significantly reduces the computational cost of high-resolution generation—boosting video inference speed to 10.1 times the original, a more than 900% improvement.
In the post-training phase, the team introduced a multi-reward Reinforcement Learning from Human Feedback (RLHF) optimization scheme. Leveraging the Group Relative Policy Optimization (GRPO) method to integrate multi-dimensional reward signals, it further enhances the model’s performance across diverse tasks.
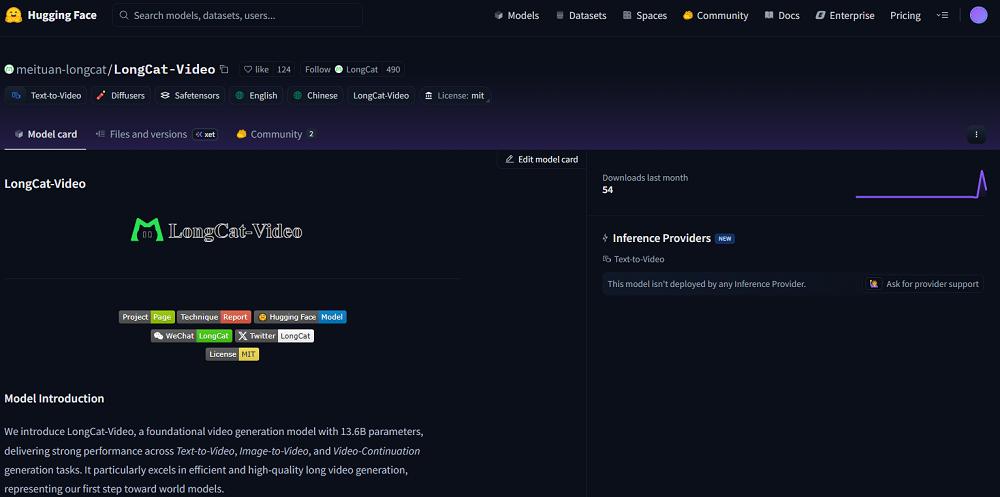
Meituan has compared LongCat-Video with other video generation large models in multiple public and internal evaluations. In the VBench public benchmark test, LongCat-Video’s overall score ranks third, only behind Veo3 and Vidu Q1. Notably, it tops all open-source models in "common sense understanding" with a score of 70.94%—surpassing closed-source models such as Veo3, Seedance 1.0 Pro, Vidu Q1, Kling 1.6, and Sora.
Currently, Meituan's LongCat-Video has simultaneously opened up its code, model weights, and key modules, with the model's technical report also released.
Meituan believes that the "World Model" has become a core engine leading to the next generation of AI. As an intelligent system capable of modeling physical laws, spatiotemporal evolution, and scenario logic, the World Model endows AI with the ability to "see" the intrinsic operations of the world.
Video generation models are expected to become a key pathway for building the World Model—by compressing various forms of knowledge (such as geometric, semantic, and physical knowledge) through video generation tasks, AI can simulate, deduce, and even preview the operation of the real world in the digital space.
To develop LongCat-Video, the Meituan LongCat team first built a data processing and annotation system at the data level.
First, in the data preprocessing phase, multi-source video collection, deduplication, s
hot segmentation, and black-edge cropping were conducted to ensure the quality and diversity of video clips.
Subsequently, in the data annotation phase, multi-dimensional attributes (including duration, resolution, aesthetic score, and dynamic information) were added to the videos, and a metadata database was established to support flexible data filtering. The team also used models such as LLaVA-Video and Qwen2.5VL to annotate video content, cinematographic language, and visual styles, and achieved text enhancement through Chinese-English bilingual translation and summary generation.
Finally, unsupervised classification and balanced optimization of video content were performed via text embedding clustering, laying a high-quality and diverse video data foundation for model training.
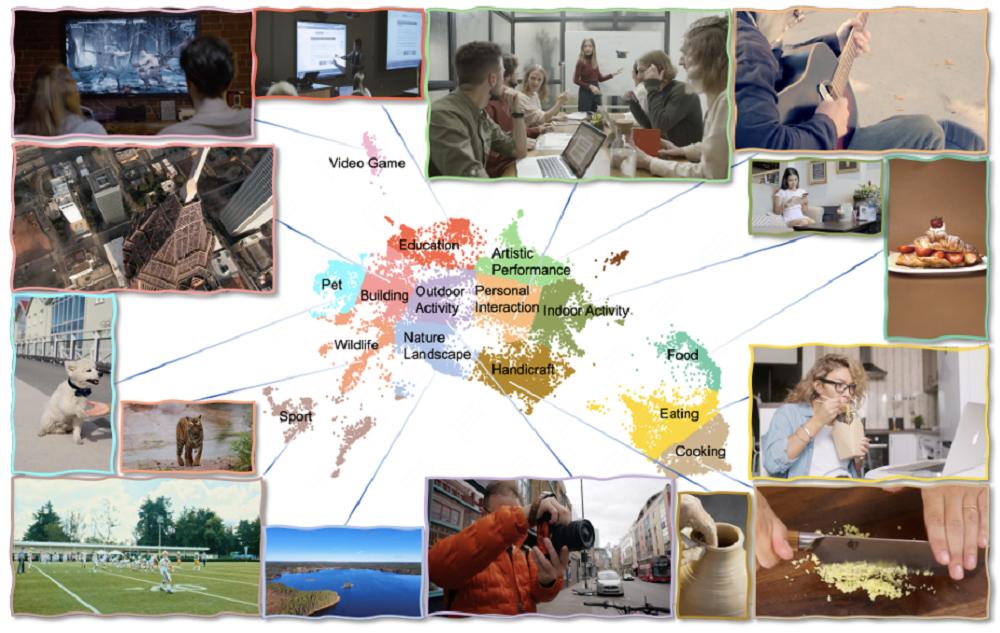
At the model architecture level, LongCat-Video adopts a single-stream 3D structure based on Diffusion Transformer, a design that combines the generative capabilities of diffusion models with the advantages of Transformer in long-sequence modeling.
Each Transformer module includes a 3D self-attention layer, a cross-modal attention layer, and a feed-forward network with SwiGLU activation, while ensuring training stability through RMSNorm and QKNorm.
The model uses 3D RoPE positional encoding to capture temporal and spatial information relationships, and introduces the AdaLN-Zero mechanism to enhance modulation capabilities across tasks.
At the input data level, the Meituan team leverages the VAE of the WAN2.1 model to compress video pixels into latent space tokens, allowing video data to participate in modeling in a more compact form with an overall compression ratio of up to 4×16×16. Text inputs are processed by the umT5 multilingual encoder, supporting both Chinese and English to further improve the model’s versatility.
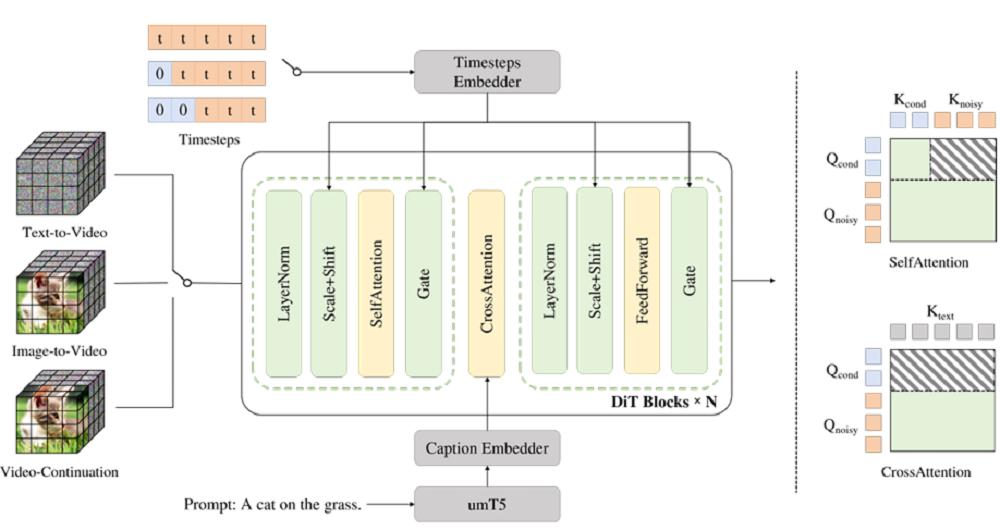
LongCat-Video adopts a three-stage training process. The model replaces the traditional diffusion process with a Flow Matching framework, enhancing training stability and efficiency by predicting the velocity field from noise to real video latent variables.
Training employs a progressive pre-training strategy, gradually learning from low-resolution images to high-resolution multi-task videos, achieving capability accumulation "from static to dynamic," and optimizing computational resource utilization through a size-bucket mechanism.
Subsequently, in the supervised fine-tuning phase, the model is refined using high-quality, diverse datasets to enhance visual aesthetics, motion fluency, and instruction understanding.
Finally, human preference optimization is introduced through reinforcement learning based on Group Relative Policy Optimization (GRPO), further improving semantic consistency and video quality.
During the training of LongCat-Video, the Meituan LongCat team innovated in task design – this is why LongCat-Video can unify three tasks (text-to-video, image-to-video, and video continuation) within a single model.
Instead of designing separate models for different video generation tasks, the team enabled all three tasks to share the same network through a "unified task framework." The model automatically determines the task type by identifying the number of "conditional frames" in the input: text-to-video is executed when input is zero-frame, image-to-video when one-frame, and video continuation when multi-frame.
This mechanism not only significantly reduces model complexity but also allows different tasks to share feature spaces and training experiences, thereby improving overall performance.
To further enhance the efficiency of long video generation, the model designed cacheable key-value features in its attention mechanism, enabling conditional frame representations to be reused during sampling and reducing redundant computations. This mechanism is particularly suitable for long video generation as it significantly lowers computational costs while maintaining consistency.
The reinforcement learning component is crucial for LongCat-Video to improve generation quality. The Meituan team made multiple improvements based on the GRPO method to adapt it to video diffusion tasks. Traditional GRPO tends to suffer from unstable reward signals and ambiguous temporal attribution in video generation. The team effectively addressed these training bottlenecks by fixing random time steps, introducing a reweighted loss function, and implementing a maximum standard deviation normalization mechanism.

▲ Comparison of Generation Effects Between GRPO Method Adopted by LongCat-Video and Baseline Methods
In terms of reward model design, LongCat-Video employs a triple reward system to evaluate video visual quality, motion quality, and text consistency respectively. Visual quality is scored by the HPSv3 model, measuring frame aesthetics and details; motion quality is assessed via the VideoAlign model to ensure natural and smooth movements; text consistency checks the semantic alignment between the generated video and input prompts.
This multi-dimensional reward design enables the model to improve performance in a balanced manner during the reinforcement learning phase, avoiding overly rigid frames or motion distortion caused by over-optimizing a single metric.
In terms of efficient inference, LongCat-Video has significantly improved generation speed and resolution through a series of engineering innovations. The team adopted a "coarse-to-fine" generation strategy: first quickly generating low-resolution, low-frame-rate videos, then using a LoRA-fine-tuned refinement module for high-definition restoration, ultimately outputting 720p, 30fps finished videos.
Meanwhile, LongCat-Video introduced the Block Sparse Attention mechanism, which only calculates the most relevant 10% of attention blocks, reducing computational costs to one-tenth of traditional methods with almost no loss in generation quality.
These optimizations allow LongCat-Video to generate one-minute-long videos in a few minutes on a single H800 GPU. Combined with consistent model distillation and Classifier-Free Guidance (CFG) distillation techniques, the number of sampling steps is reduced from the traditional 50 steps to 16 steps, and inference efficiency is increased to 10 times the original.
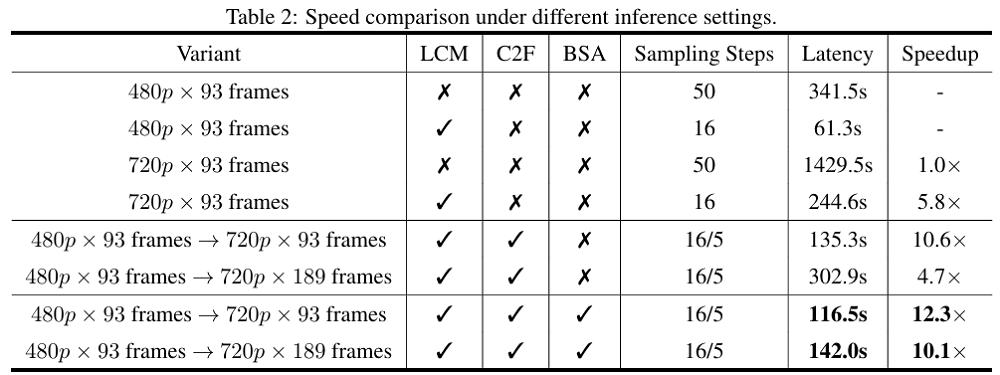
▲ Inference Speed Comparison of LongCat-Video Under Different Settings
The Meituan LongCat team shared multiple generation cases of LongCat-Video.
In the text-to-video task, LongCat-Video can accurately restore many imaginative scenes based on prompts. Cases in the video below also show its potential ability for style transfer.
It can also create the most popular AI video type recently—fruit slicing—though without sound effects, which lacks some charm.
LongCat-Video natively supports outputting 5-minute-long videos. However, in long-sequence tasks, some "continuity errors" are still noticeable. For example, in the image below, the dancer’s limbs appear unnatural during certain large movements while performing ballet.
Interestingly, Meituan shared two cases where LongCat-Video generates dashcam footage and robot dexterous hand operation scenes. Such footage could potentially be used as synthetic data for training self-driving cars and robots.
In its internal evaluation system, Meituan built a benchmark covering two core tasks: text-to-video and image-to-video. Evaluation dimensions include text alignment, visual quality, motion quality, and overall performance, with an additional image consistency metric for the image-to-video task.
To ensure scientific evaluation, the team adopted a dual-track assessment mechanism combining human and automatic evaluations. Human evaluations include absolute scoring and relative preference ranking. All samples are independently scored by multiple annotators, with final results obtained through weighted averaging.
The automatic evaluation is completed by an internally trained multimodal "judge model," which has a correlation of up to 0.92 with human results, ensuring objectivity.
Evaluation results show that in the four core metrics of the text-to-video task, LongCat-Video’s visual quality score is almost on par with Google’s Veo3, and its overall quality outperforms PixVerse-V5 and Wan2.2, a leading domestic open-source model.
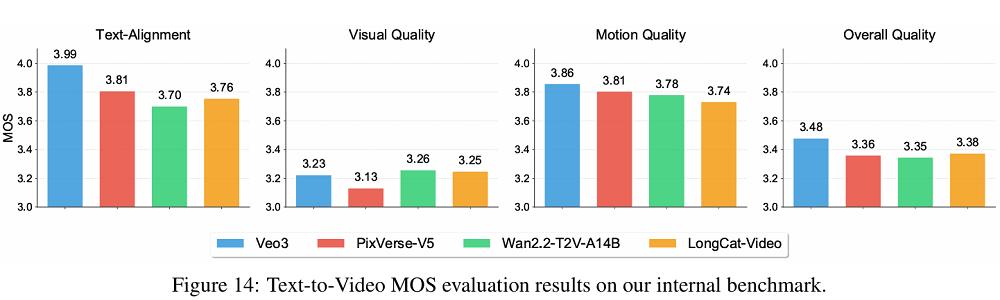
In terms of motion quality, the videos generated by LongCat-Video feature smooth movements and natural camera movements, demonstrating strong physical rationality. In text alignment, LongCat-Video performs slightly worse than Veo3.
In the image-to-video task, LongCat-Video produces videos with rich details and realistic styles, but there is still room for improvement in image consistency and motion coherence. According to the technical report, the model is relatively cautious in preserving details when processing high-precision reference frames—this contributes to its visual quality score but slightly affects dynamic smoothness.
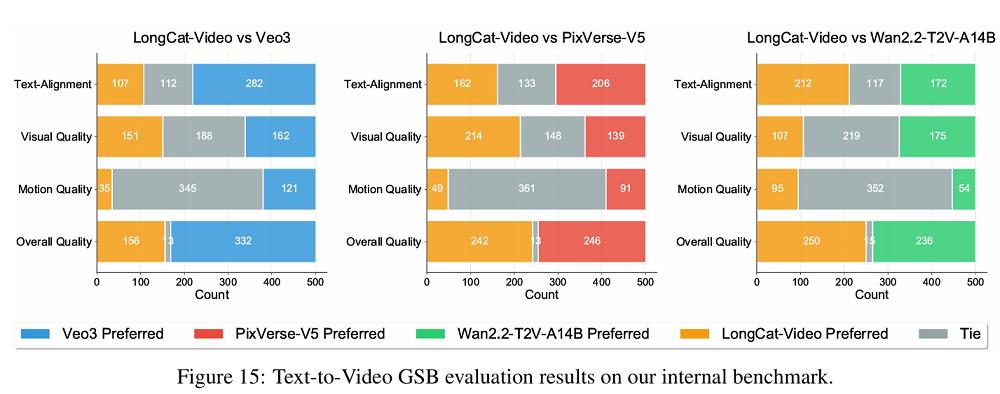
On the public evaluation platform VBench 2.0, LongCat-Video ranks first among all open-source models in "common sense understanding" with a score of 70.94%. Its overall score reaches 62.11%, second only to commercial closed-source models such as Google’s Veo3 and Vidu Q1 from Shenshu Technology.
Meituan states that LongCat-Video is its first step toward developing "world models." Efficient long video generation can address rendering challenges in world models, enabling the model to express its understanding of the world through generated video content.
In the future, Meituan plans to better model physical knowledge in video generation, integrate multimodal memory, and incorporate insights from large language models (LLMs) and multimodal large language models (MLLMs). In the demo videos shared by Meituan, LongCat-Video can accurately generate scenes such as robot operations and car driving—this may indicate that the model is expected to create certain synergies with Meituan’s business layouts in robotics and autonomous driving (driverless vehicles) sectors.